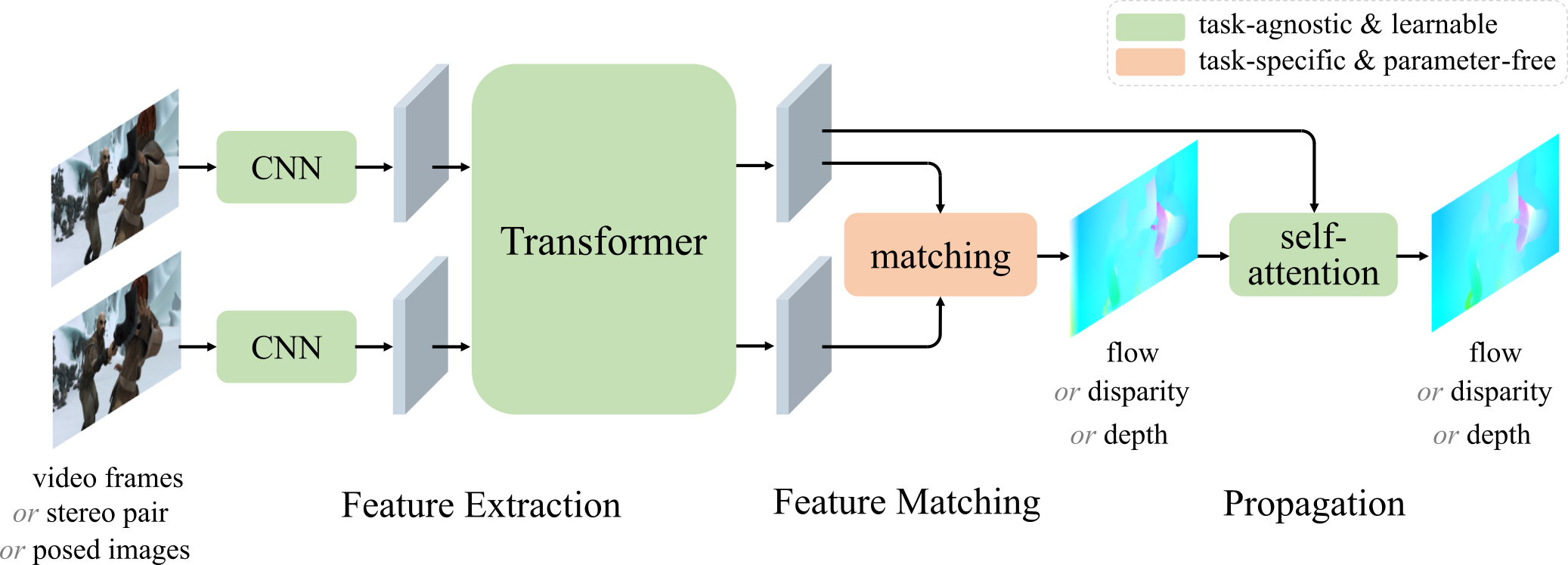
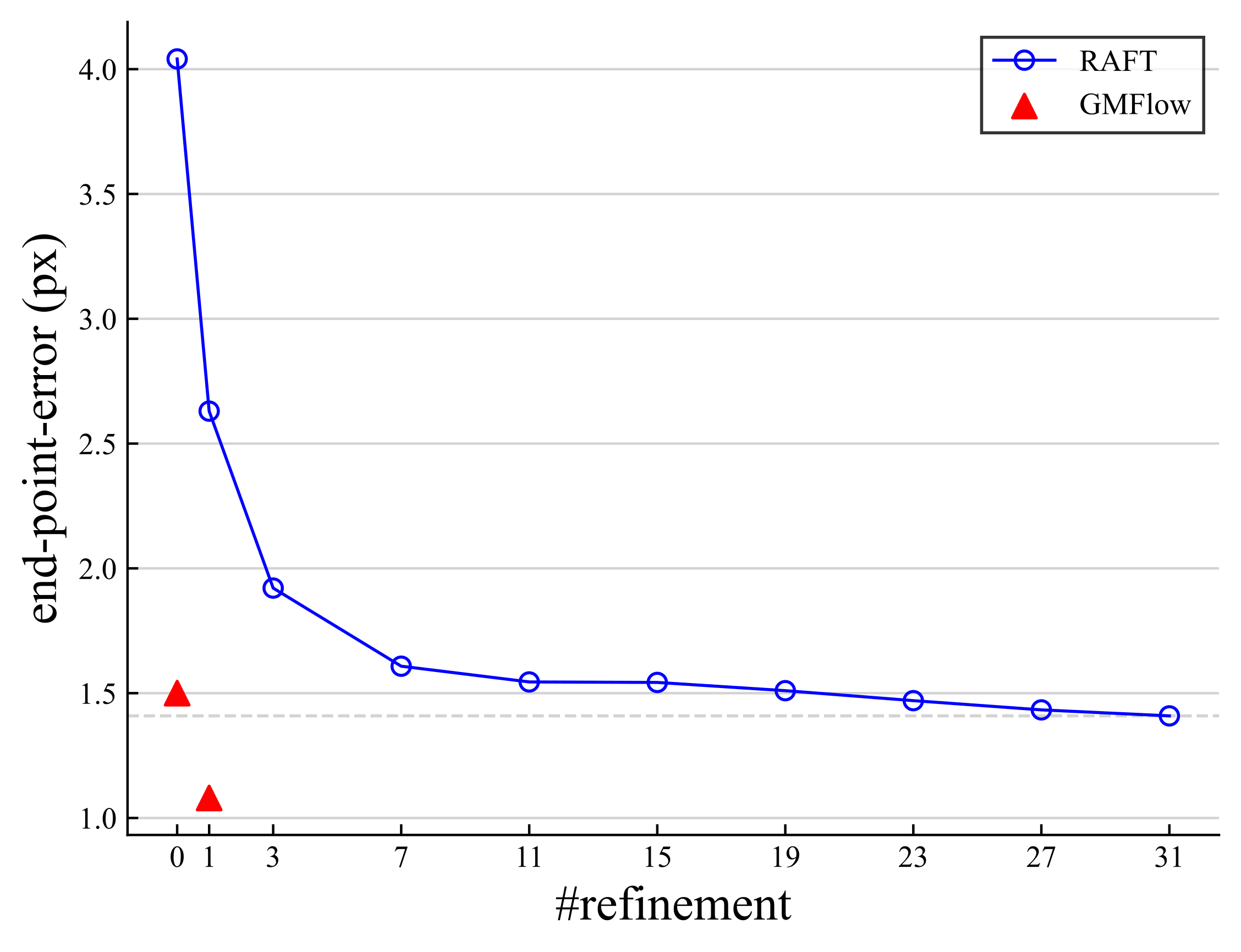
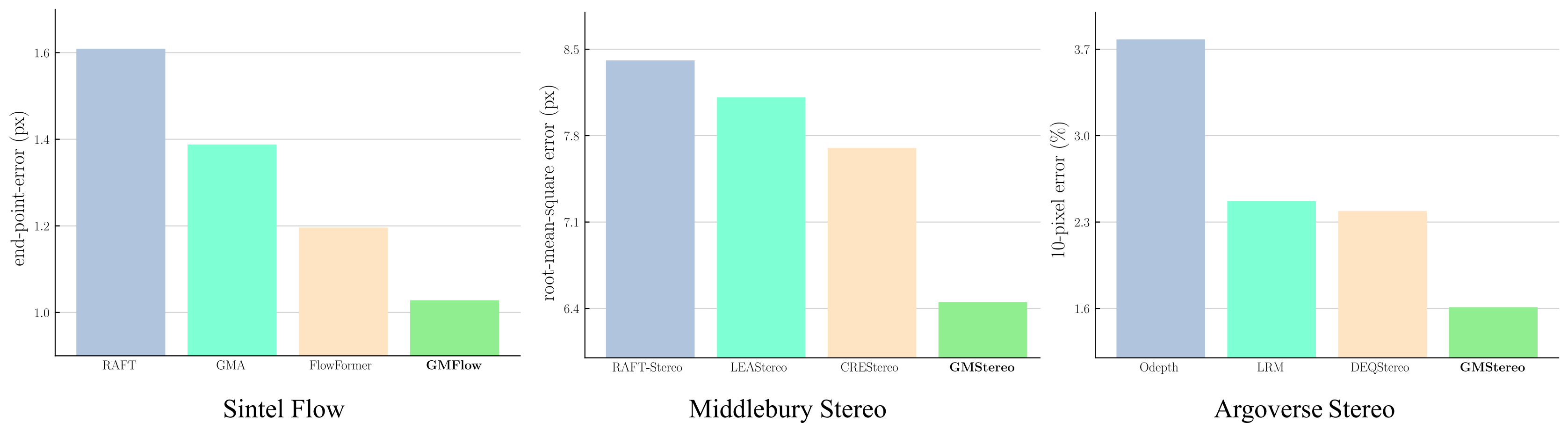
BibTeX
@article{xu2023unifying,
title={Unifying Flow, Stereo and Depth Estimation},
author={Xu, Haofei and Zhang, Jing and Cai, Jianfei and Rezatofighi, Hamid and Yu, Fisher and Tao, Dacheng and Geiger, Andreas},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023}
}
This work is a substantial extension of our previous conference paper
GMFlow (CVPR 2022, Oral), please consider citing GMFlow as well if you found this work useful in your research.
@inproceedings{xu2022gmflow,
title={GMFlow: Learning Optical Flow via Global Matching},
author={Xu, Haofei and Zhang, Jing and Cai, Jianfei and Rezatofighi, Hamid and Tao, Dacheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8121-8130},
year={2022}
}